Read deepseek-R1, although PRM can facilitates the optimization of LLMs in RL progress, they face:
- Obtaining the training data for PRM is time- and money-consuming.
- It is hard for people to accurately annotate the process reward.
- Accurate ORM is more useful that rough PRM.
📍 How to accurately annotate the PRM without human intensive? This problem is more important for Multi-hop QA / Web Search.
- Utilizing MCTS to build the PRM and combine it with the ORM to conduct RL optimization.
$$ \mathcal{L} = \mathcal{L}\text{o-DPO} + \mathcal{L}\text{s-DPO} + \mathcal{L}_\text{SFT} $$
- Shortcome: MCTS is time-consuming.
-
Translate PRM800K and Math-Shepherd from English to six additional languages and train a PRM model with best-of-N and three setups:
- PRM-MONO: train and evaluate on a single language.
- PRM-CROSS: train on one laguage but evaluate on all test languages.
- PRM-MULTI: train on seven languages and evaluate on all test languages (best performance).
-
QWEN2.5-MATH-7B-INSTRUCT as verifier (PRM) and METAMATHMISTRAL-7B / LLAMA-3.18B-MATH (fine-tuned with the MetaMath dataset) / DEEPSEEKMATH-7BINSTRUCT as generator.
-
Shortcome: Still rely on the large amount of human labeled data to train the PRM.
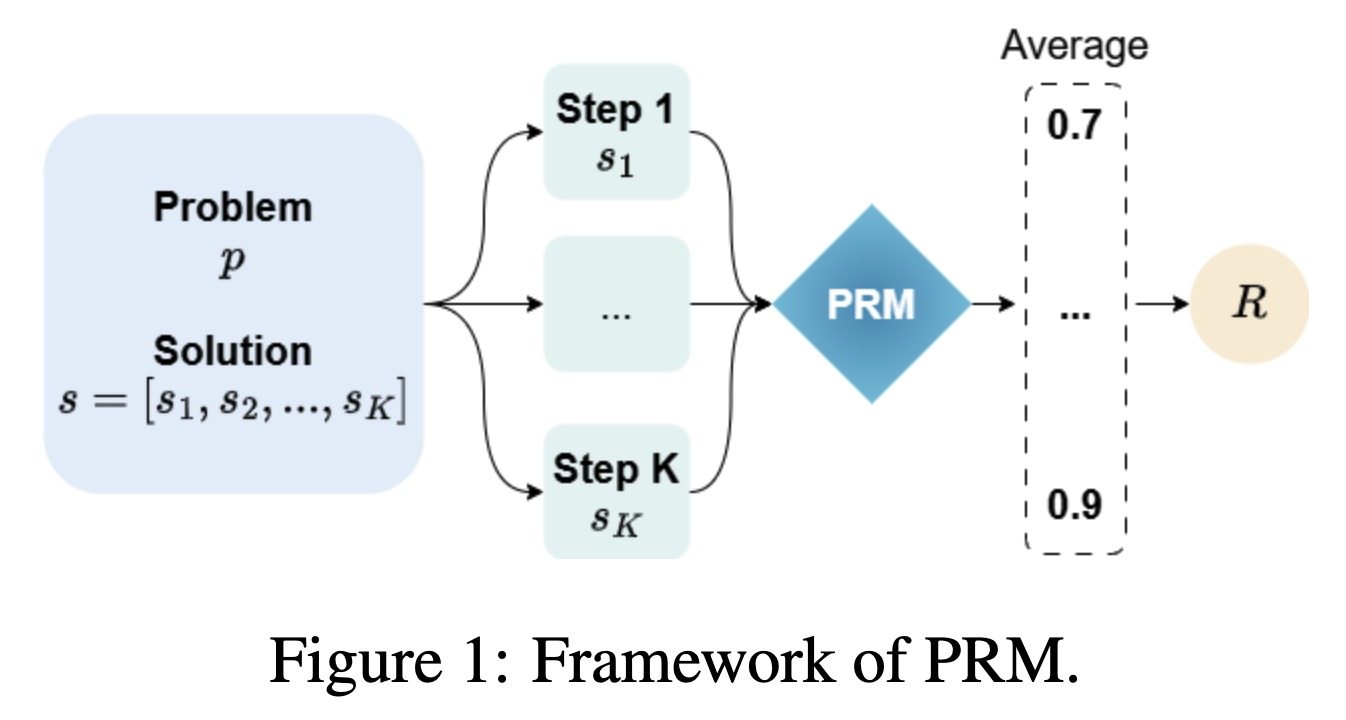
-
Distill training data from teacher model and train the reward model.
-
They use math and one-hop QA datasets.
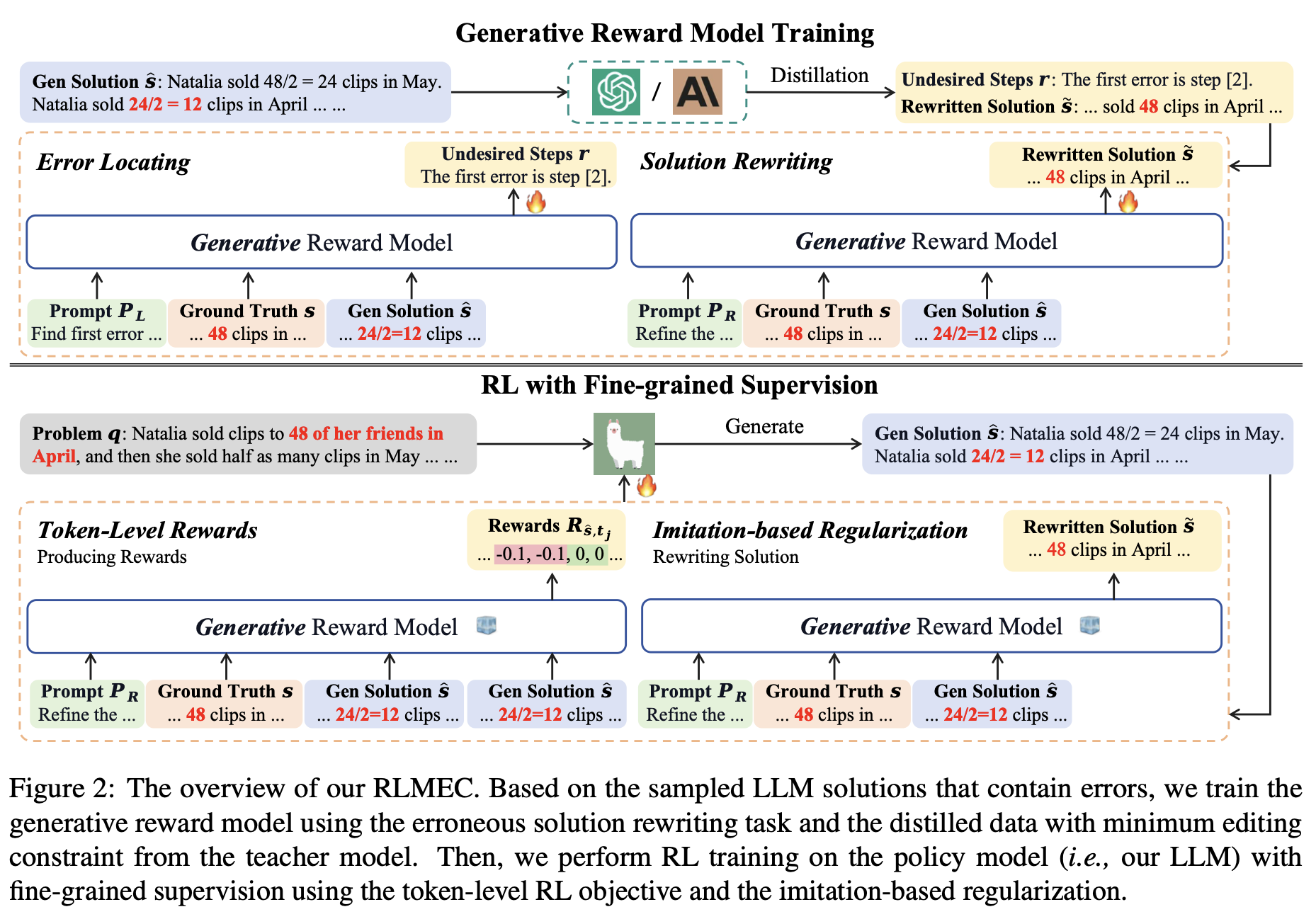
📍 For step-wise RL optimization, obtaining many labeled data is time-consuming and expensive. Moreover, human annotators are not able to provide the accurate process reward. Utilizing the teacher model to generate PRM for multi-hop QA is unreliable and they may have multiple reasoning paths. Existing PRM methods utilizing MCTS which needs to sample a large number of trajectories.
The reasoning process of math problem and code is certain and have many labeled data. If these data can be used to train the PRM for QA tasks?
- Initialize the PRM with the reward model trained on math/code dataset.
- Utilize the PRM to the contribution of each reasoning step in multi-hop QA tasks.
- Distilling a small amount of data from teacher model to train the PRM (this is not so time-consuming and practical).